全文匹配 / 语义匹配 / 混合匹配)。
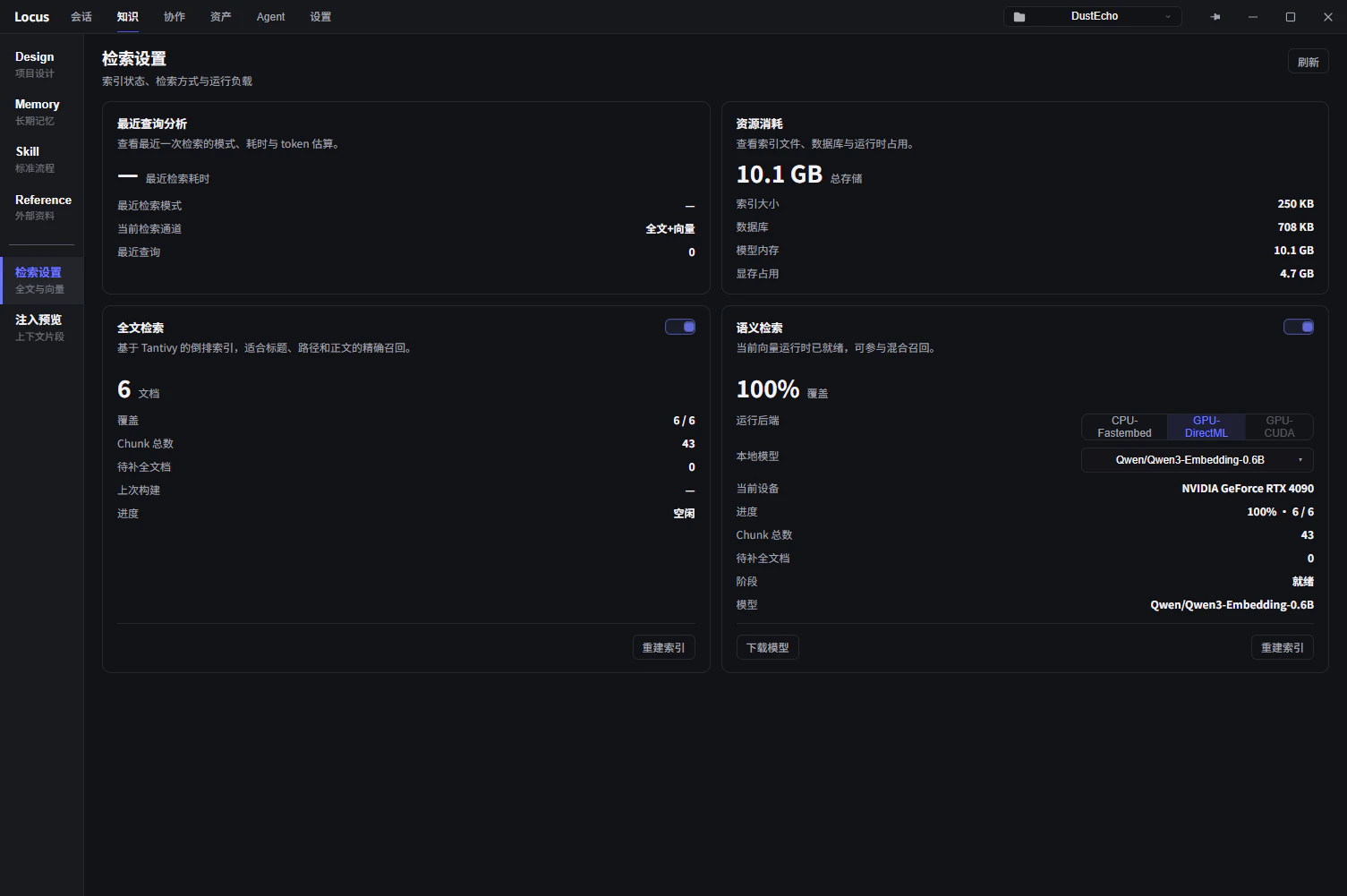
全文检索
顶部检索设置面板中的全文检索开关控制是否维护倒排索引,默认关闭。关闭时搜索栏使用逐文档文本扫描,小规模知识库够用;文档多了以后建议开启,检索更快,Agent 侧的词法召回也更完整。
语义检索
语义检索默认关闭,需要先配置 embedding 模型,两种方式:- 本地运行时:在
检索设置中选择预设模型(列表按参数规模从小到大排列,附带显存与内存估算)并下载模型,下载源可选官方或HF-Mirror;下载完成后点击激活向量启动本地运行时。也可以直接输入包含 ONNX 与 tokenizer 文件的 Hugging Face 仓库 ID,或选择本地模型目录。 - 远端接口:在「设置」页面的
嵌入设置中切换到远端模式,填写兼容 OpenAI 的/v1/embeddings接口地址、API Key与模型名,测试连接通过即可使用。
目录级开关
并非所有目录都值得进索引。目录配置的检索规则按目录控制全文检索与语义检索的参与状态,取值为继承 / 开启 / 关闭:默认沿用最近一级父目录的规则,没有上级规则时保持开启。目录树中的 LX / SM 徽标表示该目录已开启对应检索方式。体积大、价值密度低的目录(例如整包导入的原始资料)可以关闭语义检索,省下索引成本。
索引状态与刷新
- 知识总览的
检索索引卡片显示两条通道的覆盖率与最新/需刷新/待处理状态。文档修改后索引自动跟进,需刷新是正常的过渡状态。 - 状态长期异常时,用仪表盘中的
重建索引整体重建,重建进度在独立窗口中显示。 - 语义运行时的模型、当前设备与显存占用在
检索设置面板查看,停用向量可随时释放资源。